
What is a data pipeline?
A data pipeline is a set of automated processes that collect, transform, and move data from one place to another. It helps organizations manage and analyze their data efficiently by ensuring the right data reaches the right destination in the right format. In today’s digital world, data pipelines are the backbone of making smart, data-driven decisions quickly.
Types of Data Pipelines
There are mainly three types of data pipelines:
- Batch Processing Pipelines: These process data in large chunks at scheduled times. This method works well for analyzing historical data or running periodic reports.
- Streaming Pipelines: These handle data in real-time, enabling instant analysis and timely decision-making.
- Hybrid Pipelines: A combination of batch and streaming, offering flexibility based on data needs.
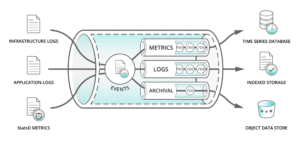
Data Pipeline Architecture
A typical data pipeline consists of three key parts:
- Sources: The origin of data, such as databases, APIs, sensors, or log files.
- Processing: Where data is cleaned, transformed, or enriched to make it usable.
- Destination: Where the data is stored or sent for analysis, like data warehouses, dashboards, or machine learning models.
Modern pipelines often use cloud-native or event-driven architectures to scale efficiently.
How Does a Data Pipeline Work?
The process flows like this:
- Extract: Data is gathered from multiple sources.
- Transform: Data is cleaned, formatted, and enriched.
- Load: The prepared data is delivered to its destination.
This automation makes data trustworthy and ready to power insights.
Data Pipeline vs ETL Pipeline
Though often used interchangeably, a Data Pipeline is a broader term covering all data movement and transformation processes. An ETL (Extract, Transform, Load) Pipeline specifically refers to extracting data from sources, transforming it, and loading it into storage. Data pipelines may also handle real-time data and more complex workflows beyond traditional ETL.
Benefits of Using a Data Pipeline
Using data pipelines offers many advantages:
- Automation reduces manual work and human errors.
- Scalability: Handles growing data volumes seamlessly.
- Improved Data Quality: Ensures consistent and clean data.
- Faster Insights: Enables real-time or near-real-time data access.
- Cost Efficiency: Optimizes resources through automation.
Use Cases of Data Pipelines
Data pipelines power many industries and applications:
- Finance: Real-time fraud detection and risk management.
- Healthcare: Integrating patient data for better care.
- E-commerce: Personalized product recommendations.
- Business Intelligence: Combining data from various sources for reporting.
Key Considerations & Challenges
While building pipelines, consider:
- Data Security: Protecting sensitive data throughout the pipeline.
- Scalability: Designing for increasing data loads.
- Fault Tolerance: Ensuring pipelines recover smoothly from errors.
- Monitoring: Keeping track of pipeline health and performance.
Popular Tools & Technologies
Some popular tools to build data pipelines include
- Cloud Services: AWS Data Pipeline, Google Cloud Dataflow, Azure Data Factory.
- Open Source: Apache Kafka, Apache NiFi, Apache Airflow.
- Analytics Platforms: Qlik, IBM Watsonx.
Future Trends in Data Pipelines
The future is exciting with innovations like
- AI Integration: Automating optimization and anomaly detection.
- Serverless Architectures: Simplifying Infrastructure Management.
- Edge Computing: Processing data closer to its source for speed.
- Data Mesh: Decentralizing data management for scalability.
Conclusion
Data pipelines are essential tools that help businesses efficiently collect, process, and use data to make better decisions. Whether it’s real-time streaming or batch processing, having a reliable pipeline ensures your data is clean, timely, and actionable. As technology evolves, data pipelines will become even more intelligent, scalable, and crucial to staying competitive in today’s data-driven world.
FAQs
What is the difference between a data pipeline and ETL?
ETL is a type of data pipeline focused on extracting, transforming, and loading data. Data pipelines cover a broader range of data processing, including real-time streaming and complex workflows.
Can data pipelines handle real-time data?
Yes, streaming data pipelines process data in real-time, enabling instant insights and quick decisions.
What are common challenges in building data pipelines?
Key challenges include data security, scalability, fault tolerance, and monitoring pipeline performance.
Which tools are best for creating data pipelines?
Popular tools include AWS Data Pipeline, Apache Kafka, Apache Airflow, Google Cloud Dataflow, and Qlik.
How do data pipelines improve data quality?
They automate data cleaning and transformation steps, ensuring consistent and accurate data is delivered to users.